Features
DeepKE is a knowledge extraction toolkit supporting cnSchema, standard supervised, low-resource and document-level scenarios for entity, relation and attribution extraction. It allows developers and researchers to customize datasets and models to extract information from unstructured texts.
Low-resource
DeepKE supports low-resource setting with only a few labelled (e.g., 16/32 shot) instances for widespread information extraction tasks.
Document-Level
Since relations are expressed over multiple sentences in real-world applications, DeepKE supports document-level relation extraction.
Multimodal
DeepKE supports multimodal entity and relation extraction tasks, which can enhance the extraction performance through visual cues.
Online Demo
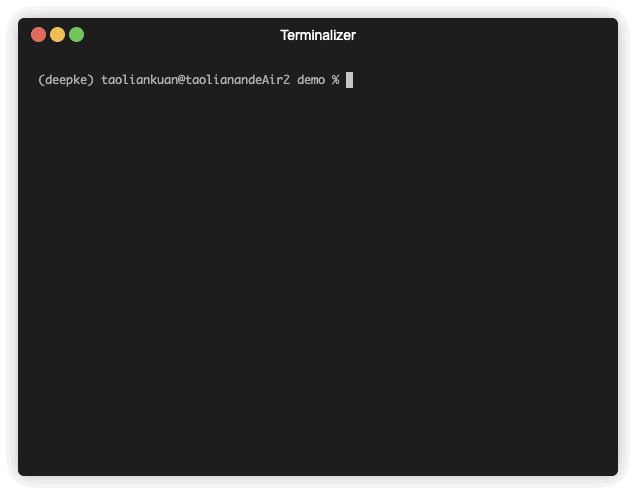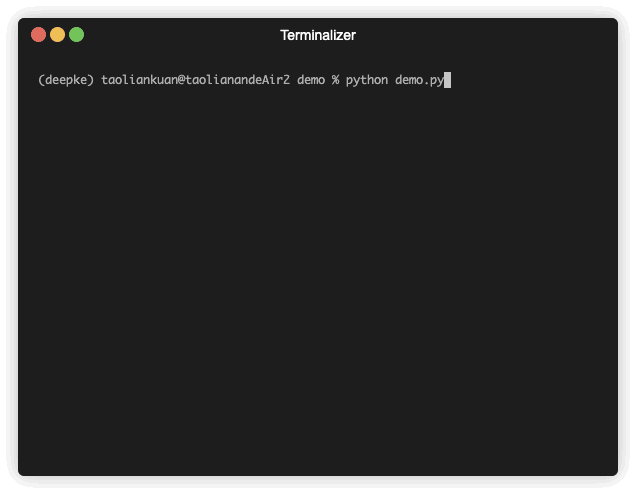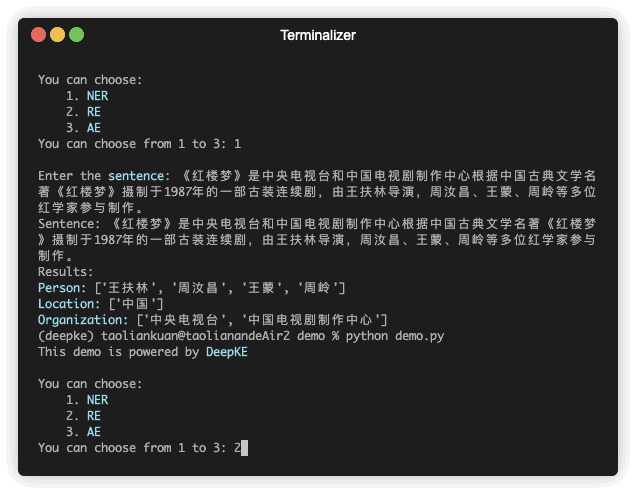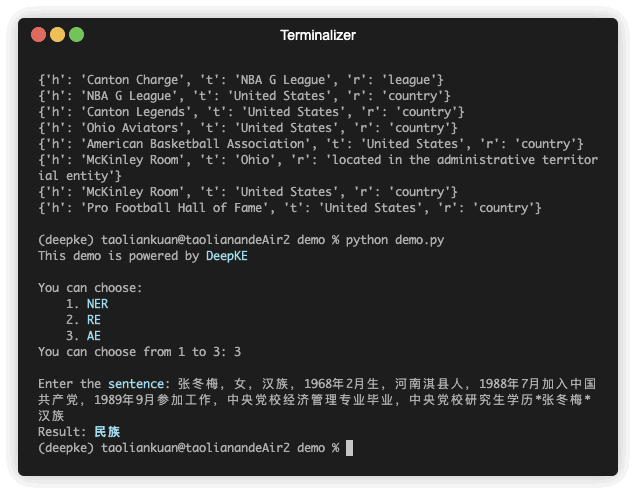
We provide an online system to extract knowledge from the text with friendly interactive interfaces and fast reaction speed. Click here to try it !!
Open-sourced toolkit to extract knowledge
We present a new open-source and extensible knowledge extraction toolkit, called DeepKE, supporting standard fully supervised, low-resource few-shot and document-level scenarios. DeepKE implements various information extraction tasks, including named entity recognition, relation extraction and attribute extraction. With a unified framework, DeepKE allows developers and researchers to customize datasets and models to extract information from unstructured texts according to their requirements. Specifically, DeepKE not only provides various functional modules and model implementation for different functions and scenarios but also organizes all components by consistent frameworks to maintain sufficient modularity and extensibility. Moreover, DeepKE has quipped with comprehensive documents as well as Google Colab tutorials for beginners. Users can install DeepKE via 'install deepke'. We will provide maintenance to meet new requests, add new tasks, and fix bugs in the future.
Flexible usage
DeepKE provides various functional modules and reganizes all components by consistent frameworks. DeepKE provides off-the-shelf extraction models with Chinese pre-trained language models based cnSchema.
Sufficient modularity and extensibility
The training & evaluation codes and model implementation are separated for easy usage.
Support automatic hyperparameter tuning
An off-the-shelf automatic hyperparameter tuning component is available.
8
Issues
34
Stars
45
Forks
Application Scenarios
Toolkit Design and Implementation
Off-the-shelf Models
Broad Domains
Supporting cnSchema
Contributors

Ningyu Zhang, Liankuan Tao, Xin Xu, Haiyang Yu, Hongbin Ye, Shuofei Qiao, Xin Xie,Xinrong Li, Xiang Chen, Zhoubo Li, Lei Li, Xiaozhuan Liang, YunzhiYao, Shumin Deng, Peng Wang, Wen Zhang, Guozhou Zheng, Huajun Chen

Haofen Wang

Qiang Chen, Feiyu Xiong

Zhenru Zhang, Chuanqi Tan, Fei Huang




